一个中文信息处理系统必须考虑许多语言自身与结构方面的知识——如什么是词、词如何组成句子、词的意义是什么、词的意义对句子意义有什么贡献等,但这些却还是远远不够的。比如一个系统如果要回答提问或者直接参与对话,它不仅需要知道很多语言结构的知识,而且还要知道人类世界的一般性知识并具备人类的推理能力。因此许多语言学家通常把对语言的分析和理解分成如下几个主要层次:词法分析、句法分析、语义分析、篇章分析。
但是,在中文信息的处理当中会遇到各种困难,而最主要的是一下两方面:
首先,是汉字切分歧义问题。汉语言本身存在歧义。对人来说,一般是通过上下文来理解,但是机器很难正确判断该如何切分。比如对“组合成机器”来说,“组合”、“合成”都是词,到底是切分成“组合/成”还是切分成“组/合成”?歧义一般来说按照结构可以分为“交叉歧义”和“覆盖歧义”。
其次,是汉语未登录词识别问题。未登录词指的是词典中没有收录的词,包括各种命名实体(如数词、人名、地名、机构名、译名、时间、货币)和网络新词(如坑爹、酱紫、快女、给力)等。另外,一些缩略语(如科协)和术语(如股骨头坏死)也属于未登录词的范围。
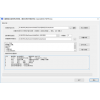
NLPIR/ICTCLAS分词系统是针对互联网内容处理的需要,融合了自然语言理解、网络搜索和文本挖掘的技术,具有深度学习、高效、语义的特点,可以支持中英文分词与词性标注,可视化系统可根据词性对不同的分词结果进行区分显示,一般虚词都是浅色,而名词、动词、形容词等实词为显著的颜色。系统还支持在线用户词典的输入,用户可以在右下方添加用户词及词性。
NLPIR/ICTCLAS2016分词系统主要功能介绍
1)中英文混合分词功能
自动对中文英文信息进行分词与词性标注功能,涵盖了中文分词、英文分词、词性标注、未登录词识别与用户词典等功能。
2)关键词提取功能
采用交叉信息熵的算法自动计算关键词,包括新词与已知词。
3)新词识别与自适应分词功能
从较长的文本内容中,基于信息交叉熵自动发现新特征语言,并自适应测试语料的语言概率分布模型,实现自适应分词。
4)用户专业词典功能
可以单条导入用户词典,也可以批量导入用户词典。如可以定“举报信 敏感点”,其中举报信是用户词,敏感点是用户自定义的词性标记。
5)微博分词功能
对博主ID进行nr标示,对转发的会话进行自动分割标示(标示为ssession),URL以及Email进行自动标引。
NLPIR/ICTCLAS运行环境
1 、支持的环境
1). 可以支持Windows、Linux、FreeBSD等多种环境,支持普通PC机器即可运行。
2). 支持GBK/UTF-8/BIG5
2、 Linux如何调用NLPIR
1)与window下一样编程;
2)Makefile的命令如下:
test: ../../../Src/ICTCLAS2013/example-c/Example-C.cpp ../../../Src/ICTCLAS2013/include/NLPIR.h
g++ ../../../Src/ICTCLAS2013/example-c/Example-C.cpp -L. -lpthread -L../../../bin/ICTCLAS2013 -lNLPIR -Wall -Wunused -O3 -DOS_LINUX -o ../../../bin/ICTCLAS2013/example
其中Example-C.cpp是测试使用NLPIR的程序;因为NLPIR进行了多线程的安全保护设计,需要调用多线程的库,即-L. –lpthread。调用nlpir的部分为:-L../../../bin/ICTCLAS2013 –lNLPIR **部分为路径,后面为libNLPIR.so对应的名称-lNLPIR。